Building Data Pipelines Part 2: Stream To S3 Storage and DynamoDB Pipeline and query transaction data in DynamoDB


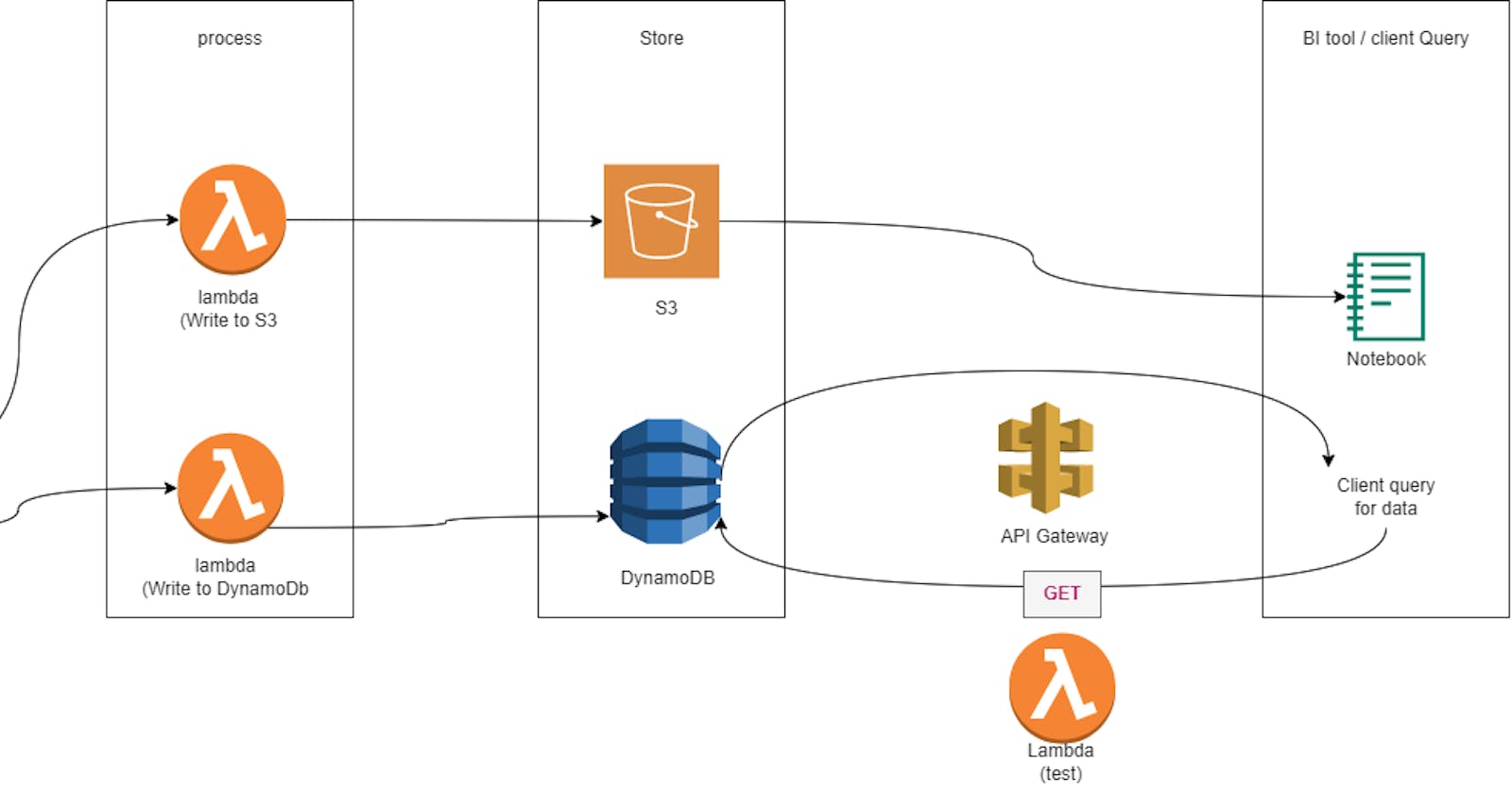
In this phase, we will focus on sending data from Kinesis to storage (S3 and DynamoDB) and querying transaction data in DynamoDB using an API.
Stream to s3 raw storage
Configure IAM for S3
Create lambda function to insert data into S3
Test the pipeline
Setup DynamoDB
Setup IAM for DynamoDB Stream
Create DynamoDB Lambda
Query Data in DynamoDB
Overview

Our pipeline involves continuously pulling raw CSV data into the system, storing transformed data in S3 and DynamoDB, and connecting this data to Business Analytics tools such as Tableau and Jupyter Notebook. Additionally, customers can utilize an API to query transaction data in DynamoDB using primary key parameters (InvoiceNo & Stockcode).
Setting Up S3 Bucket
Kinesis Data Stream and Lambda Integration: Set up Kinesis data stream insert triggers, configure IAM roles for S3 and create Lambda to write messages to the S3 bucket as files.
Lambda Function for Data Cleaning and Transformation (Optional): Add a Lambda function to clean and transform raw data, converting types to Parquet and adding a timestamp (InvoiceDate).
Testing the Pipeline: Utilize the Lambda test function to configure test events, ensuring a successful event sends test data to S3, confirming the Lambda function's functionality.
Stream to DynamoDB Pipeline
Kinesis Trigger and Lambda for DynamoDB: Configure Kinesis inserts to trigger Lambda for DynamoDB, where the Lambda preprocesses data and writes customer and invoice data.
DynamoDB Table Creation:
Customer Table:
Keys: "Partition key - CustomerID (String)" and "Sort Key - InvoiceNo (String)"
Columns: Country, Description, InvoiceDate, Quantity, Stockcode, UnitPrice
Invoice Table:
Keys: "Partition key - InvoiceNo (String)" and "Sort Key - StockCode (String)"
Columns: Country, Description, InvoiceDate, Quantity, UnitPrice
Lambda Function Configuration: Create a Lambda function that processes incoming Kinesis data records, updating both 'Customers' and 'Invoices' DynamoDB tables. Assign the necessary IAM roles for Kinesis and DynamoDB access.
AWS Kinesis Stream Trigger Configuration:
Open AWS Lambda service in the Management Console.
Select the desired Lambda function.
In the designer panel, click "Add trigger" and choose "Kinesis."
Configure the trigger settings, including batch size and starting position.
Enable the trigger.
Check the Data: Ensure the data is stored correctly by testing the pipeline.
Connecting to Business Analytics Tools
Connect the stored data in S3 and DynamoDB to Business analytics tools such as Tableau and Jupyter Notebook for advanced analysis and visualization.
Enabling Customer Queries via API
In this phase, we introduce a GET request to the initial Lambda function, allowing customers to access and query transaction data in DynamoDB.
Creating a Request to Retrieve Transaction Data in DynamoDB
Check the URL in API Gateway Stages for the GET method.
import pandas as pd import boto3 import io from botocore.exceptions import NoCredentialsError AWS_KEY = 'YOUR_ACCESS_KEY' AWS_SECRET = 'YOUR_SECRET_KEY' BUCKET_NAME = 'your-bucket-name' FILE_NAME = 'your-file-name' s3 = boto3.client('s3', aws_access_key_id=AWS_KEY, aws_secret_access_key=AWS_SECRET) try: obj = s3.get_object(Bucket=BUCKET_NAME, Key=FILE_NAME) data = obj['Body'].read() df = pd.read_parquet(io.BytesIO(data)) except NoCredentialsError: print("No credentials provided")Using Postman:
Go to the "Create a request" menu.
Enter the URL and add key-value pairs (InvoiceNo & Stockcode).
Get the response from DynamoDB with the new URL.
The implemented data pipelines execute the ETL process, facilitating the extraction of insights. Moreover, seamless connectivity to BI analytics tools empowers efficient data visualization. Further updates including screenshots to enhance the project are in progress.